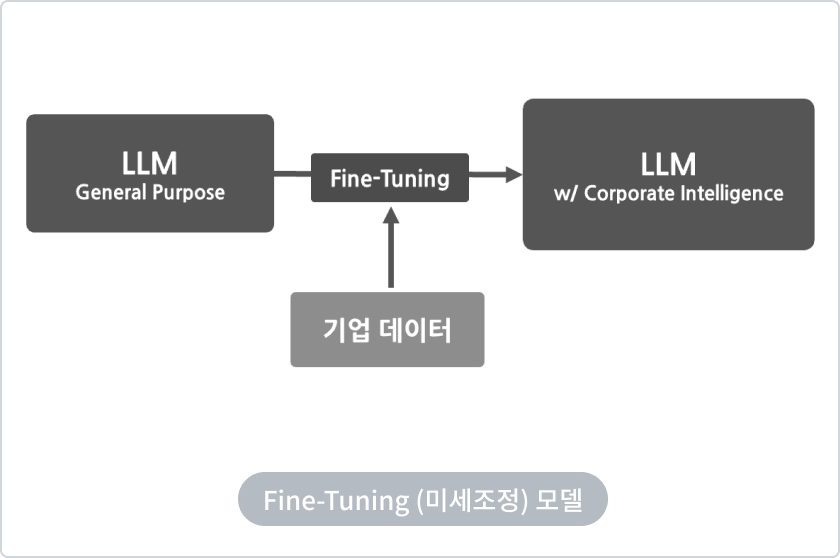
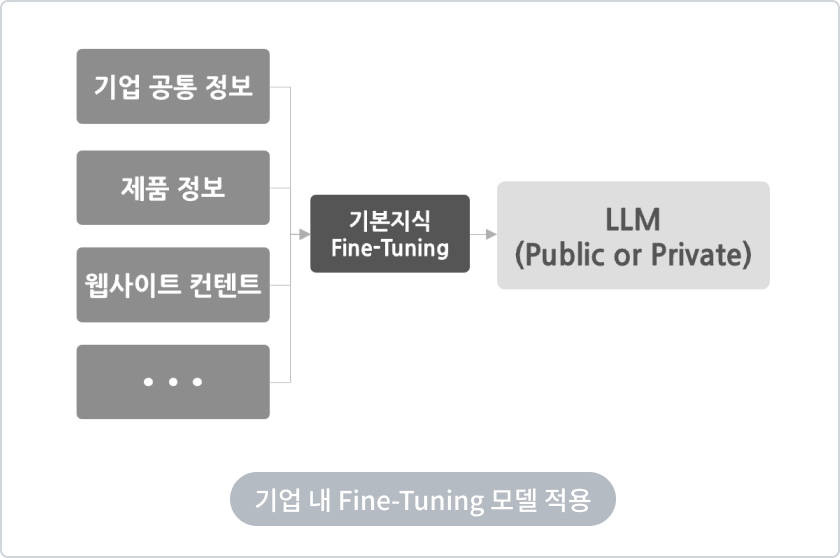
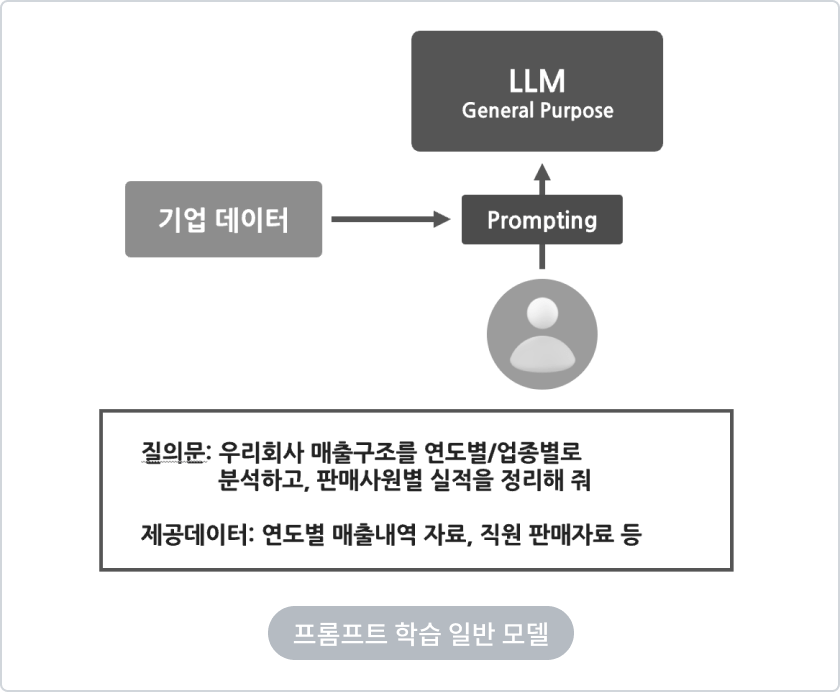
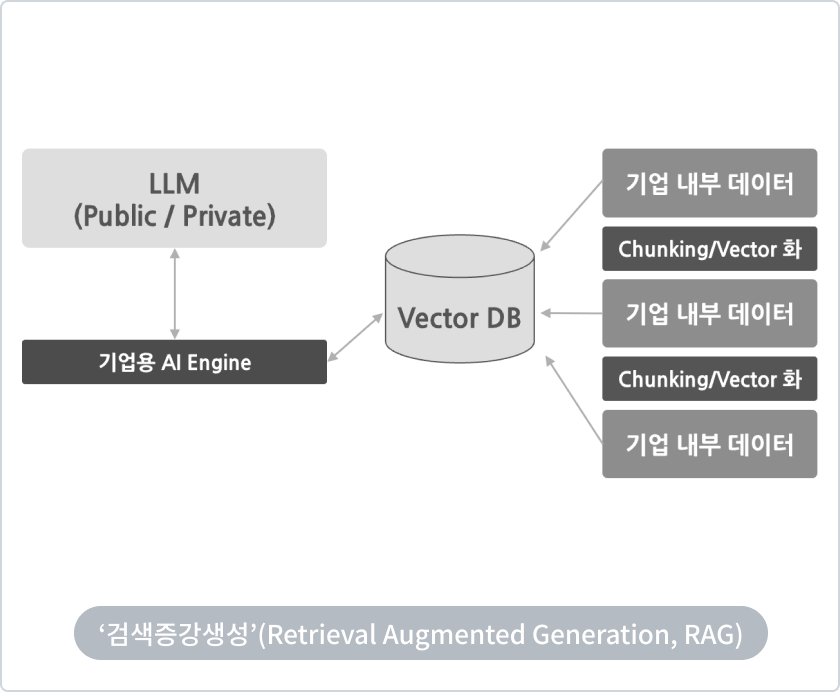
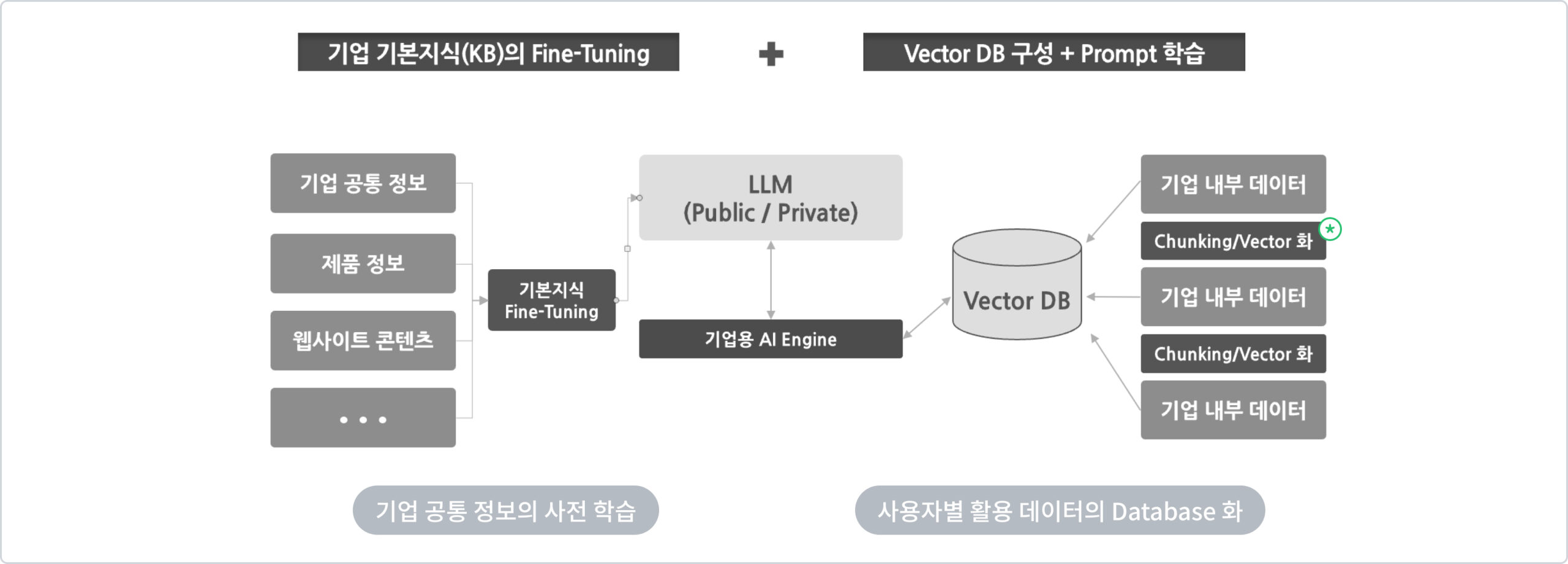
Chunking / Vector화
Vector화는 텍스트를 숫자 벡터로 변환하는 작업입니다. 텍스트를 컴퓨터가 이해할 수 있는 형태로 변환합니다.

 상담 챗
상담 챗

